今回、QiitaでChatGPTなどの活用方法を発信しよう!という企画をやっていたので、参加してみました。
自分が投稿したこちらの記事と同じ内容です。
今回は最近流行りのChatGPTを高度情報技術者試験に応用するとどんな感じになるか、試してみました。
今回題材に使ってみたのは、[令和3年度のシステムアーキテクト午前2の問題](https://www.ipa.go.jp/shiken/mondai-kaiotu/gmcbt8000000d5ru-att/2021r03h_sa_am2_qs.pdf)です。
# 試しに問1を解かせてみる

そうすると、以下の回答が出てきます。

おーーーーっ、正解だ!
# 続いて問19を解かせてみる

ChatGPTの回答はこちら。
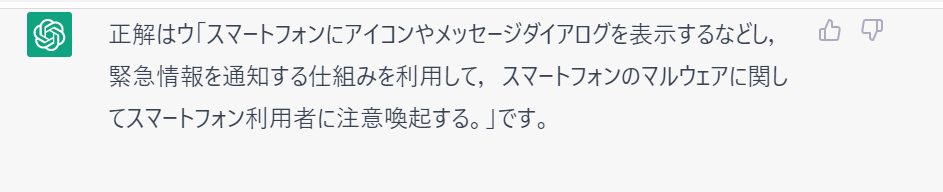
正解は「イ」なので、これは外れです。
AIも間違えることはあるということか。

ちゃんと間違いを認めて謝罪するのは素直だな(笑)、と思ったら今度は向こうが問題を出してきた:open_mouth:

とりあえず回答すると答えと解説を出してくれたけど、1回目の解説が前の問題の解説のままだ・・・
# とりあえず25問解かせてみた

正解数は19問。おーーーーっ、合格だ!自分はギリギリセーフの15問だったので、俺より優秀なのか:sweat_smile:っていうかしっかり勉強しろ俺。
# 超大雑把にまとめてみる
とりあえず、ITが生み出しただけあって、IT分野については普通に優秀ですね。たまに間違えることがあるのでファクトチェックは必要ですが。
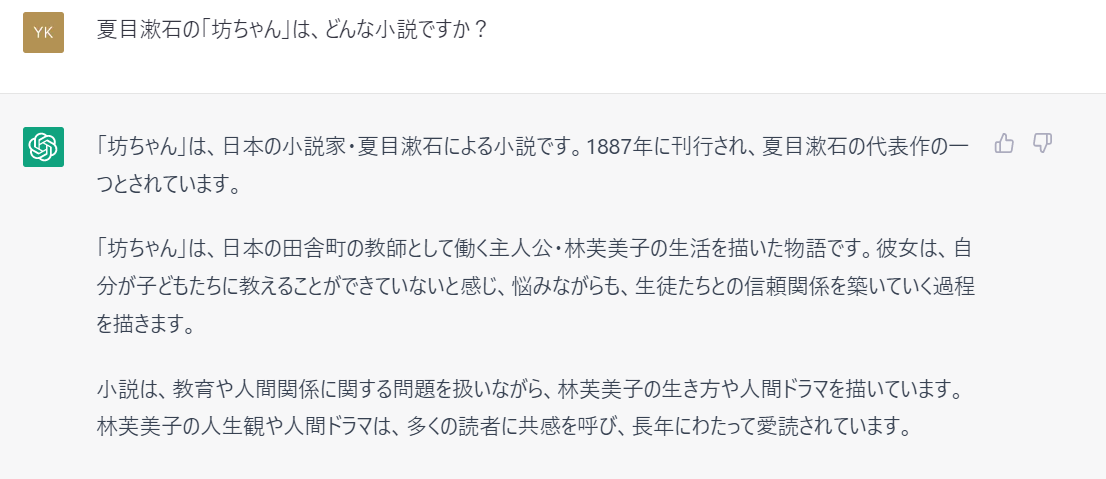
ただ、分野によって得意不得意が激しいみたいなので、例えば夏目漱石の「坊ちゃん」について聞いてみたら、デタラメもいいところでした:scream: